
Are you ready for the next outage or degradation in performance? Do you have your incident response plan in place? During the last few years, we have witnessed several instances when massive service providers have experienced outages that have cost companies billions.
Let’s take for instance Amazon’s S3 outage earlier this year (February 28, 2017). Some estimate that outage alone, lasting only a few hours, could have cost upwards of $150 million. One single service disruption caused degradations and disruptions to 48 other internal services they have listed on their service health dashboard. One of the lessons to be learned from this event. They host their own status page, which itself was impacted by the outage, resulting in the status indicators not displaying the red outage icon. As a result of not having their page hosted by a third party, it put additional stress on their support team.
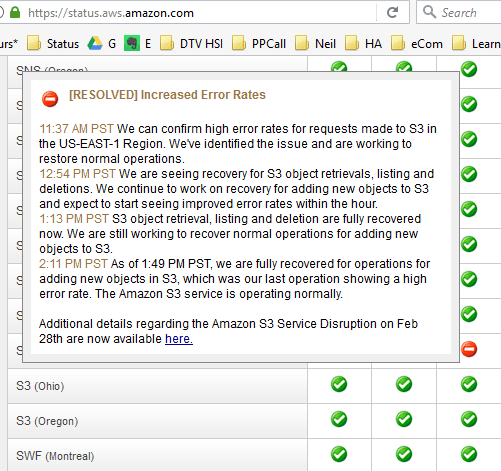
This is a continuous risk of modern IT organizations, as we have become dependent on SaaS services. The days of hosting your own complex datacenters are over and the future of IT looks to integrate existing services in a meaningful way.
Modern services and applications are typically built on top of a backbone that is hosted offsite and out of the IT organization’s control. These great technological dependencies have created a need for these services to be available 24/7/365 and we have seen what can happen when they are not. I am willing to bet that you have several services that either partially or solely depends on a third party vendor.
Who Needs an Incident Response Plan?
Modern business means that you are providing some sort of IT service to your customers or end users. This is consistent no matter the size of your business and the number of your employees you have. From the diner on the corner to the tech giant, all businesses are dependent upon IT services.
Let’s think about this for a minute and think about the small diner on the corner. There are a lot of logistics behind the scenes for this diner to operate. They must have Internet connectivity to order food and supplies. They must have an Internet-connected POS system to accept credit card payments (who has cash anymore). This POS system is also tracking what was ordered and therefore integrated with an inventory control system.
This diner must be ready for an incident just as much as your tech giant SaaS provider that has millions of clients. What will they do when these services fail? How will they notify their staff? How will they notify their customers? What secondary systems are in place in case the first ones fail? These things can be planned before there are problems and detailed in your incident response plan. The time to take action is not when you are in crisis mode, you should be prepared for the day when your systems will fail.
Incident Response Planning
The Incident Response planning phase is the most intensive and important aspects of your response plan. This is the stage that you are going to lay the foundation and put in all the hard work to develop your plan, process and procedures. This is the kickoff point and is critical to your overall success.
During the planning phase, you should develop training and make sure that all of your staff attends the same training. It is important that all of your employees have the same incident response training and are familiar with the various roles that they may fill. This is also a good time to plan any drills to test your processes throughout the lifecycle of your plan.
As a matter of practice, you should host bi-annual drills within your organization to prepare your staff for an outage. This will ensure that your staff gets an opportunity to experience an outage in the sandbox before the stressful real-world incident. Furthermore, spacing these 6 months apart will account for any attrition that you have within your organization and will be a continuation of the onboarding training that your staff should be receiving.
Incident Response Process & Considerations:
What is an incident?
The popular ITIL framework defines an Incident as an unplanned interruption to an IT Service or reduction in the quality of an IT service. This is a broad definition and there are typically other factors that go into your incident response decisions:
Here are some factors that should be considered:
- Impact – How many customers have to be impacted?
- Urgency – What are the effects if the Incident is not resolved in a timely manner?
- Time – How long do you foresee the Incident affecting a service?
Incident Response
There are many components to your incident response plan and these should include:
- Incident Response Roles
- Incident Commander
- Internal Communication Plan (Staff)
- External Communication Plan (Customers)
- Time Metrics
Incident Response Roles
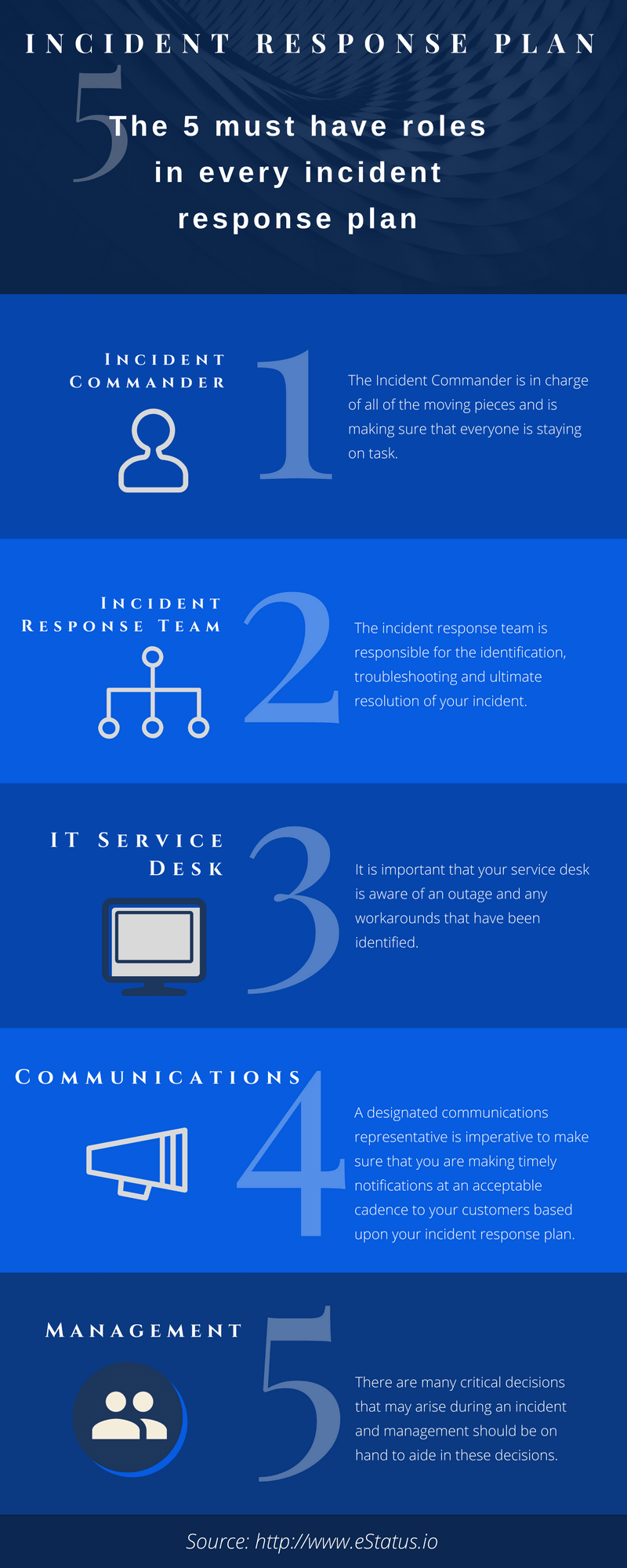
There a many moving parts within your incident response procedures but the role of your staff are most critical to your success. The following roles should be considered and applied to your plan:
- Incident Commander
- Incident Response Team
- IT Service Desk
- Communications
- Management
Incident Commander
The Incident Commander is responsible for the incident and has several duties throughout the lifecycle of an incident. He or she should know what is expected of them during this role and proper proactive training should be given throughout your company. Training should not happen during a live incident.
The Incident Commander is in charge of all of the moving pieces and is making sure that everyone is staying on task. These duties include but are not limited to:
- Resource Assignment
- Communication Coordination
- Notifications
- Documentation (Log activities throughout the event)
- Resolution
- After action: (Lessons Learned, etc.)
Incident Response Team
The incident response team is responsible for the identification, troubleshooting and ultimate resolution of your incident. These teams can be small or large and will vary between organizations and industry. However, the key to having a great incident response team is to make certain that you have enough resources to handle any incident that may arise.

There are some key positions that should be included on your incident response team:
- IT Service Desk
- Security Analyst
- Developers (Yes- really.)
- Database Administrators
- Server Administrators
- Application Administrators
- Network Administrator
IT Service Desk
Your service desk is your hub and the tip of the iceberg for your organization. Typically all of the work that flows through your organization is originated at the service desk. This is also the place that users will contact when you are experiencing an outage. It is important that your service desk is aware of your outage and any workarounds that have been identified throughout the identification or troubleshooting processes.
I cannot reiterate this enough that you must keep your service desk informed during any outage. I have seen the consequences notifying the service desk as an afterthought and it is a recipe for a disorganized chaotic mess. Build this into your plan and make sure you have mechanisms in place to make these critical notifications.
Communications

Communication during an outage is critical to your overall success. Too little or too late and you have a herd of angry customers banging down your doors. Too much communication – wait that never happens so we can skip that. A designated communications representative is imperative to make sure that you are making timely notifications at an acceptable cadence to your customers based upon your incident response plan.
While often a separate role, this role can be shared on within your response team. However, this role should be hyper-focused on internal and external communication and not have to share the burden of troubleshooting, etc. To avoid any missteps it is recommended that this resource is free to manage the communications process.
Management
Your various team and department management should be available during a problem but should not interfere in the incident response steps the team needs to carry out. There are a lot of critical decisions that may arise during an incident and management should be on hand to aid in these decisions or approve any emergency changes, etc.
Internal Communication Plan
During an incident, it is critical to alert your internal support and technical teams. These are the people that need to start diagnosing the Incident and moving towards a resolution. This is typically the most critical piece of your plan and should involve a solution to notify all of your technical teams and use a swarming technique to address the incident.

This swarming technique breaks through the typical IT silos and brings all of your technical experts together to quickly identify root cause and move towards resolution. Your technical teams will work collaboratively and not have to worry about a strict chain of command during the identification of root cause. This leads to faster root cause identification and ultimate incident resolution.
External Communication Plan
The next critical piece of communication is to your customers or end-users and this can take place simultaneously to your internal communication or immediately after. This will vary from business to business and other incident impact and urgency factors will go into this determination. Find a solution that works for you and your business.
Customers will start flooding your service desk or business phone at the first sign of a problem and this can cost a company millions during major outages. In 2017 we should be providing proactive communications to users and avoiding the costly IT phone call to report an issue that we already know is happening. There are several communication methods that may work for your business:
- Company Status Page
- Email Notifications
- SMS Notifications
- Message on your support line
- Social Media Accounts
The goal here is to get the information in front of your customers so that they are informed and so that they are not flooding your IT help desk with costly support calls. Furthermore, studies show that proactive notification methods reduce customer stress and instill confidence.
A company status page is how modern organizations communicate with their customers and this will be discussed in greater detail later in this article. The comprehensive solutions provide a status page and communication platform that your customers will love. Consider your plan before you next outage strikes.
Time Metrics
Time metrics are critical to your incident response policy and give you a benchmark for making decisions. You should assign time limits to various events and have an action plan to execute once these thresholds have been met or exceeded. For example, maybe you have an internal incident triage time of 15 minutes. During this initial 15 minutes, your support teams are identifying the problem and trying to get a grasp on the impact. At the 15 minutes mark, you should be sending your external communication or activating the necessary communication channels.
Status Page
A status page at a basic level is a website that customers can visit to see the status of your applications and services. This provides an interception point between a customer detecting a problem and flooding your IT help desk with calls. The customer now has a single reference point to check to inquire about the status of your critical services.
Modern status pages are hosted by a third party and provide several features to include email communication, SMS communication, historical data, etc. A status page is a great tool to have in your Incident Response Plan and will provide the transparency into your organization that customers expect.
Conclusion
SaaS happens everyday and you want to be proactive as opposed to reactive in your Incident Response planning. It is critical to provide your staff with a step-by-step guide to aid them in times of crisis. The internal process and procedures are the most time consuming and this is where you have to put in a lot of hard work.
Furthermore, IT outages have become very expensive and it is important to restore service as fast as possible. These include providing timely communication and notifications to your customers. It is important that your customers have a single point/place of contact for the status of your services and that they are able to get communications and notifications about the services that are important to them.
Lastly, you have to plan for the unexpected so that when the unexpected happens it is expected. This includes documenting your process, procedures and plans. You should also train your staff and make sure that everyone within your organization shares the same baseline incident management knowledge. Also, it is critical that you stage outage drills to practice your skills and to put your plan through the rigors before the next outage.